The raw data for this project is comprised of three different sets of oral history and sociolinguistic interviews with New Yorkers:
1. The Bronx Oral HIstory Project
2. Bronx African American History Project
3. The CUNY Interviews: The majority of the data for this project derives from the hard work of our undergraduates at the City University of New York, specifically at the College of Staten Island, Lehman College, and Queens College — who have enthusiastically and successfully engaged with members of their own communities to produce the interviews that form the basis of the CUNY-CoNYCE. See acknowledgments for a list of individuals. Because of the age demographic of our undergraduates, close to 75% of our interviewees for the 1.0 publication of the corpus were born from the 1980s onward. The following charts summarize the demographics of this version of the corpus:
Racial Composition:
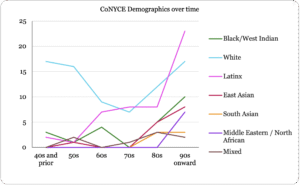
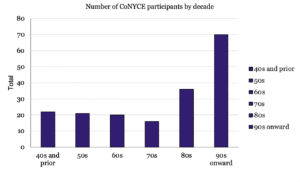
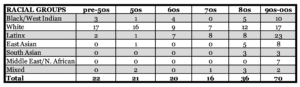
Notes:
Black/West Indian includes participants identifying themselves as African Diaspora, primarily including descendants of those kidnapped and enslaved in the US, mostly arriving in NYC through the Great Migration, and later arrival from the West Indies, Haiti, and Africa. At times it was impossible to determine whether an individual was of Afro-West Indian origin or Indo-West Indian origin, particularly those of Trinidadian and Guyanese origins. So those two groups are joined here.
East Asian includes participants identifying themselves as Korean, Chinese, Filipino, Tibetan Vietnamese, or Thai backgrounds
South Asian includes participants identifying themselves as of Indian, Pakistani, Bangladeshi, Sri Lankan or Afghan backgrounds
White includes participants of European origins plus any from Central Asia who identified themselves as white.
Middle Eastern/North African includes all those from Arabic speaking countries in addition to Turkey, and Iran.
Latinx includes those whose origins are in Latin America. Because there were no participants who identified themselves as of Brazilian background, they all have familial or current Spanish linguistic backgrounds.
Mixed includes those who so identified but also a few who listed no racial background and we could not determine their background.
Gender Composition
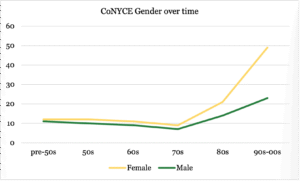

Notes: Gender is based on interviewer and participant identification. No participant identified themselves as non-binary.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.